Revealing Disocclusions in Temporal View Synthesis through Infilling Vector Prediction
Vijayalakshmi Kanchana, Nagabhushan Somraj, Suraj Yadwad and Rajiv Soundararajan
Indian Institute of Science
Technical Talks on this work
- WACV 2022:
- 24-Sep-2021: In IISc Student Research Seminar Series, 2021. [Video]
Sample comparison videos with other competing methods
Abstract
We consider the problem of temporal view synthesis, where the goal is to predict a future video frame from the past frames using knowledge of the depth and relative camera motion. In contrast to revealing the disoccluded regions through intensity based infilling, we study the idea of an infilling vector to infill by pointing to a non-disoccluded region in the synthesized view. To exploit the structure of disocclusions created by camera motion during their infilling, we rely on two important cues, temporal correlation of infilling directions and depth. We design a learning framework to predict the infilling vector by computing a temporal prior that reflects past infilling directions and a normalized depth map as input to the network. We conduct extensive experiments on a large scale dataset we build for evaluating temporal view synthesis in addition to the SceneNet RGB-D dataset. Our experiments demonstrate that our infilling vector prediction approach achieves superior quantitative and qualitative infilling performance compared to other approaches in literature.Temporal view synthesis for frame rate upsampling
Alternate frames are graphically rendered and the intermediate frames are predicted using temporal view synthesis.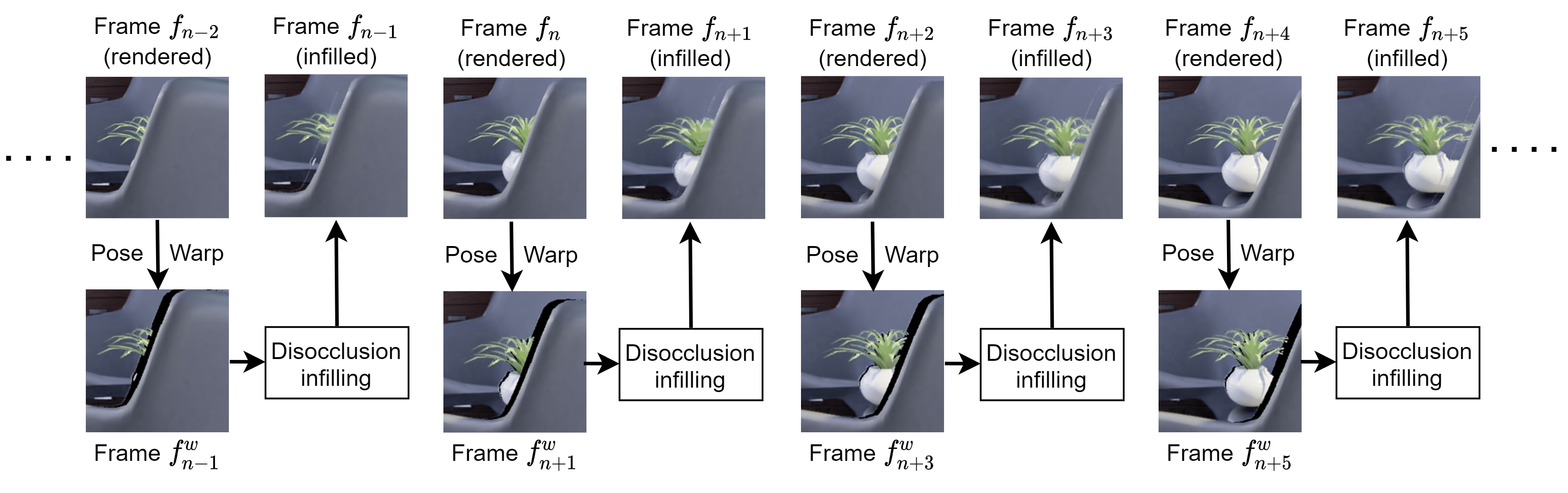
Infilling Vectors - Idea
Disocclusions can be infilled by copying intensities from the neighborhood background regions, pointed by the predicted infilling vectors.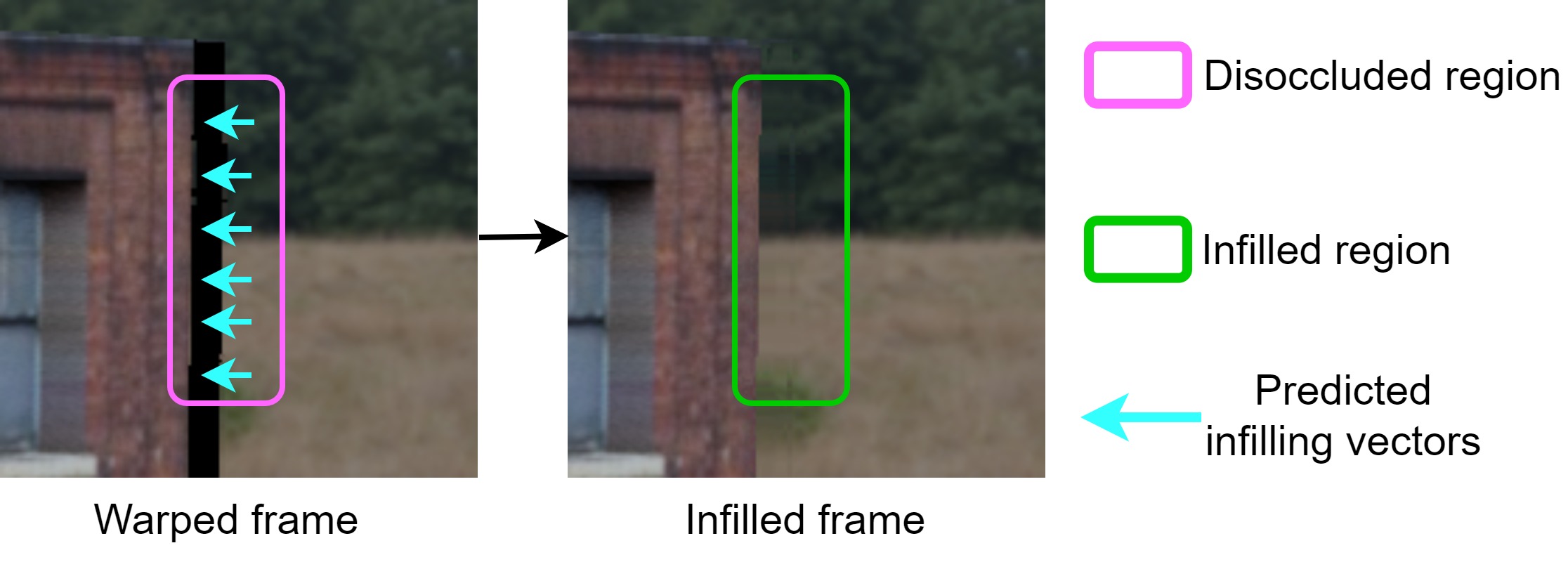
IISc VEED Database
The database consists of 200 diverse indoor and outdoor scenes (see samples below). We use Blender to render the videos. We obtain the blend files for the scenes mainly from blendswap and turbosquid. 4 different camera trajectories are added to each scene and thus we have a total of 800 videos. The videos are rendered at full HD resolution (1920 x 1080) and at 30fps and contain 12 frames each.

Citation
If you use our work, please cite our paper:
Vijayalakshmi Kanchana, Nagabhushan Somraj, Suraj Yadwad and Rajiv Soundararajan,
"Revealing Disocclusions in Temporal View Synthesis through Infilling Vector Prediction",
In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022.
Bibtex:
@inproceedings{kanchana2022ivp,
title = {Revealing Disocclusions in Temporal View Synthesis through Infilling Vector Prediction},
author = {Kanchana, Vijayalakshmi and Somraj, Nagabhushan and Yadwad, Suraj and Soundararajan, Rajiv},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
pages = {3541--3550},
month = {January},
year = {2022},
doi = {10.1109/WACV51458.2022.00315}
}
title = {Revealing Disocclusions in Temporal View Synthesis through Infilling Vector Prediction},
author = {Kanchana, Vijayalakshmi and Somraj, Nagabhushan and Yadwad, Suraj and Soundararajan, Rajiv},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
pages = {3541--3550},
month = {January},
year = {2022},
doi = {10.1109/WACV51458.2022.00315}
}